When Complex is as Simple as it Gets: Guide for recasting policy and management in the Anthropocene, along with a useful schematic, can now be found at
I’m hardly the first to have been struck by the analytic tip in my profession, policy analysis: What used to be dealt with at the local, regional and even national levels, at least when I started out in the early 1970s, must now be addressed first and foremost globally (think “global warming”). What I was unprepared for was how “the local” has been consigned to analytic oblivion as the tip proceeded.
Let me give an example from the field of Infrastructure Studies. To be clear, I agree with every word in the following:
Infrastructures should be understood as plural, active, and dynamic, producing a range of impacts, both planned and unplanned, on the places and societies they traverse and inhabit. These insights reinforce the characterization of infrastructures as socio-technical networks, while their multiple and often ambiguous effects partially challenge the intentionality presumed in [Michael Mann’s 1984] conceptualization of infrastructural power. For example, recent scholarship highlights the unanticipated costs or forms of violence that infrastructures can impose on disenfranchised communities and regions.
The socio-technical nature of infrastructures is clearly reflected in their politicization and contestation, which reveal competing social interests across multiple scales. Commonly regarded as background systems, infrastructures rarely occupy public attention until they fail to meet expectations, whether through malfunction, inadequate supply, or clashes with users’ interests and needs. Increasing attention has also been paid to infrastructures’ negative externalities, or “public bads,” including ecological, social, and psychological harms, revealing both conflicting local perspectives and broader changes in societal priorities and beliefs, as well as new forms of collective identity and agency, manifested in labor strikes, acts of sabotage, or protests. (https://journals.sagepub.com/doi/10.1177/1368431026145776; internal citations deleted)
To me, this passage represents hard-won insights over years of research, namely: the units and levels of analysis are socio-technical, networks, across scales, contingent on context, and often with unanticipated and unintended impacts.
But then comes the irresistible updraft in the article’s next sentence:
These dynamics are not confined to the local scale: transnational infrastructures are increasingly implicated in broader geoeconomic contexts, as exemplified by the Houthi attacks on the Red Sea shipping lanes, the shutdown of major Chinese ports under Beijing’s zero-COVID policy, and the disputes surrounding the Nord Stream 2 gas pipeline.
Well, yes, that’s true of course, but still: Just what is happening at the lower scales of analysis? Indeed, how do actual operations of critical infrastructures unfold at the local and regional levels?
The article, like so many others, is off and runningto the international, global and now planetary levels–understandably so, since that’s analytic tip after all–but: Even if what the article continues to say is just as true as the above quotes, that truth needs to be pushed further, especially as variation in inter-infrastructural connectivities at the local and regional levels matter so often and so directly for policy and management.
NB. For more on this analytic tip, see my 1994 Narrative Policy Analysis.
GMMTV, the producer of Thai BLs, may yet screw this series up, but something very very special has been building over the first three episodes: finding love in spite of dark times.
As now. When we are told that everything–repeat, everything–is political, even something as political as “God’s sons” can transcend itself when the script, music, cinematography, acting and chemistry of the two male leads excel like this. The culmination in the last scene of episode 3 has a life of its own.
Let me state my conclusion upfront: in the policy and management world I know best, human agency is the only genuinely global counternarrative I’ve encountered.
Because human agency is constrained differently across times, places, and conditions, it plays a more important role than hegemonic or universalized policy narratives like that for human rights. The human agency counternarrative persists — even as dominant policy narratives shift — precisely because it is not tied to any single macro-framework.
First, a working definition: human agency is “an individual’s capacity to determine and make meaning from their environment through purposive consciousness and reflective and creative action.” My version emphasizes reflexivity; others might stress self-determination or the capacity to act on one’s environment. Either way, I think the points that follow hold across most reasonable definitions.
II
To clarify what I mean by human agency, consider two examples — one from migration studies, one from research on child labor:
Specifically, the current mainstream narrative is one that looks at these people as passive components of large-scale flows, driven by conflicts, migration policies and human smuggling. Even when the personal dimension is brought to the fore, it tends to be in order to depict migrants as victims at the receiving end of external forces. Whilst there is no denying that most of those crossing the Mediterranean experience violence, exploitation and are often deprived of their freedom for considerable periods of time (Albahari, 2015; D’Angelo, 2018a), it is also important to recognize and analyse their agency as individuals, as well as the complex sets of local and transnational networks that they own, develop and use before, during and after travelling to Europe.
Schapendonk, J. (2021). “Counter moves. Destabilizing the grand narrative of onward migration and secondary movements in Europe.” International Migration: 1 – 14 https://doi.org/10.1111/imig.12923
The relationship between young people and organized crime is complex and multifaceted. Young people are victims of acute marginalization, poverty and violence but they do have some agency over their decision making. The data from all studies illustrated how gangs offer young people ways to earn an income but they also provide social mobility, ‘social protection’ (Atkinson- Sheppard, 2017) and ‘street capital.’ In some instances, criminal groups offer young people ways to earn ‘quick and easy money.’ Thus, the young people are not devoid of agency, but their decision making should be considered within the context of restricted and bounded lives.
Atkinson-Sheppard, S. (2022). “A ‘Lens of Labor’: Re‐Conceptualizing young people’s involvement in organized crime.” Critical Criminologyhttps://doi.org/10.1007/s10612-022-09674-5
III
With those examples in mind, let’s first turn to four positions often taken with respect to “human agency.”
There are those who think human agency is among core precepts around which to design large-scale systems involving humans, individually or collectively (think philosopher Kant and “human autonomy”). Others are more apt to focus on the individual or micro-level, where the agent acts under case-specifics. Whether at the macro- or micro-levels, contestation abounds over the term, human agency, if only because of different optics on the micro and macro from psychology, phenomenology, law, economics, and more.
There are, however, two other levels and units of analysis, which are the ones I want to focus on with respect to human agency as the global counternarrative.
Far less mentioned than the micro and the macro are really-existing better practices for realizing human agency–in your or my definitions–that have evolved and over widely different cases. Then there are also the cases where macro-precepts are modified over contingency scenarios that vary subnationally, regionally or more “locally”. In both instances, human agency is better understood as an insistent counternarrative for moving away from the current dominant micro- and macro-level narratives of human agency.
IV
From this vantage point, sweeping claims about human agency applying to or governing all cases are simply unworkable in a world shaped by highly variable system(s) patterns and highly variable local conditions.
Human agency as a counternarrative emerges from a run of different cases; it is not an a priori position from which to assert macro-principles or micro-experience. Human agency in this way becomes sufficiently granular to be actionable when applied and modified to the next case at hand. The limitation of staying at the macro and/or micro positions, e.g., “human rights apply uniformly to every single individual on this planet,” is that these positions degranularize the highly differentiated real-time conditions for taking action between whole system and single person.
An example helps. A recent article “questions the analytical and empirical dominance of the term ‘resistance’ and contends that the term may at times obscure the proactive, enduring and often existential dimensions of political action which might be better captured by the term ‘struggle’” (https://www.tandfonline.com/doi/full/10.1080/2158379X.2026.2681610). An earlier article on resistance, however, finds:
As is often noted, resistance is a term that seems impervious to stable definition. The term has a number of conceptual neighbours which are not quite its synonyms, and sometimes even function as its antonyms: dissent, rebellion, opposition, revolt, insurrection, revolution, protest, civil disobedience and conscientious objection. (https://www.tandfonline.com/doi/full/10.1080/01916599.2018.1473955; internal footnote deleted)
Oops, no ‘struggle’ in that list either.
Just as I distrust speculative metaphysics, so too I distrust discussions framed around macro-levels of terminological abstraction. Meanings are in the uses of the respective term and differentiated uses emerge across a range of events, situations, contexts, and applications. What looks like “resistance to a state-imposed agenda” in one place may look like “the defense of still-evolving practices” somewhere else. Any serious account of human agency as a counternarrative has to be that nuanced if it is to reflect the work in transforming policy and management systems already shaped by macro-principles and a few decision-makers.
The trouble with calls for big-T transformation is not just their gravitational pull toward abstraction. It’s that advocates for such transformations do not sufficiently admit the starting-point legitimacy of really-existing better practices that have evolved but still diverge from master plans. Better a billion small, practice-based just-transitions than the handful currently proclaimed in principle for the globe.
A recent article “questions the analytical and empirical dominance of the term ‘resistance’ and contends that the term may at times obscure the proactive, enduring and often existential dimensions of political action which might be better captured by the term ‘struggle’” (https://www.tandfonline.com/doi/full/10.1080/2158379X.2026.2681610). An earlier article on resistance, however, finds:
As is often noted, resistance is a term that seems impervious to stable definition. The term has a number of conceptual neighbours which are not quite its synonyms, and sometimes even function as its antonyms: dissent, rebellion, opposition, revolt, insurrection, revolution, protest, civil disobedience and conscientious objection. (https://www.tandfonline.com/doi/full/10.1080/01916599.2018.1473955; internal footnote deleted)
Oops, no ‘struggle’ in that list either.
Just as I have distrust speculative metaphysics, so too I distrust discussions at these levels of terminological abstraction. Meanings are in the uses of the respective term and differentiated uses emerge across a run of different events, situations and contexts (cases). What is called resistance of state-imposed agendas here might well be seen defense of still-evolving practices there.
Say, you are a policy analyst tasked by your agency to produce a desk-top report answering, “What’s the risk of flooding in downtown Helsinki due to changing sea levels, storm surges, and inland run-off because of climate change in the next decade or two?”
You look first for existing probability and risk estimates, and not just in official documents but also in the grey literature of engineering and consultants’ reports, including modeling and simulation findings. Unsurprisingly, given the fragmentary findings, you recommend, among other priorities, increasing the resilience of existing flood management and emergency management infrastructures to better respond to the unpredictabilities ahead.
In this iteration, you–and we–start with risk and work our way to calling for more resilience as part of the solution portfolio, especially for (though not exclusively) the critical infrastructures directly involved in flood and emergency response.
I argue that it’s a very misleading approach to start out with considerations of risk and resilience and end up with implications for infrastructure change. The analysis looks very different when you begin with the existing infrastructures, how they are actually managed for the physical systems actually operated on the ground, and then look for the risks (and resiliencies) that come with managing the sociotechnical system(s) that way or those ways, now that changing climate conditions have been posed as above.
II
So return to the starting question: “What’s the risk of flooding in downtown Helsinki due to changing sea levels, storm surges, and inland run-off because of climate change in the next decade or two?”
Questions of risk/resilience are only raised afteranswering two logically and empirically prior questions, if infrastructures start the analysis. First the analyst has to answer:
Q1. What are the infrastructure systems of concern and how are they operated and managed on the ground? It’s of course not just flooding and emergency management infrastructures you are concerned with, but lifeline infrastructures interconnected with the two, not least of which are energy (e.g., electricity), transportation, telecommunications and water supplies (including wastewater). Even more important is the focus on how these systems operate in real time, irrespective of how they are supposed to operate because of design, regulation or technology blueprints.
Q2. What are the standards of reliability and safety to which these systems are actually managed (e.g., if it is managed to a precluded-event standard, what are the events that must never happen—for instance, urban water supplies should not be contaminated by cryptosporidium or LSD, the electricity grid should not island, airplanes should not drop from the sky all over the place)?
Once Q1 and Q2 have been answered and only then does our analyst ask and answer:
Q3. What then are the risks and resiliencies to be managed that follow from meeting these standards for those systems as they operate in real time and over time on the ground?
Of course, much of the above (as below) is compressed. Still, it’s safe to say much of the critical infrastructure literature starts with a version of Q3—the risks to be managed (let alone other unpredictabilities)—without answering the two prior questions. Ignoring questions about operational boundaries and standards and starting instead with the third serves to import economic and engineering assumptions about optimal reliability into the analysis that are not empirically correct. When spatial boundaries and reliability standards are not addressed first, it is too easy to reduce “management” to an altogether unrealistic choice: Do I, the decisionmaker, take on more or less risk in light of my optimality criteria? That is one huge way operational mismanagement can and has happened.
III
Now let’s unpack Q2 and Q3 in more useful detail: What are the different standards of reliability and safety? and What are the different risks and resiliencies that follow from these respective standards? What, then, about important interconnections?
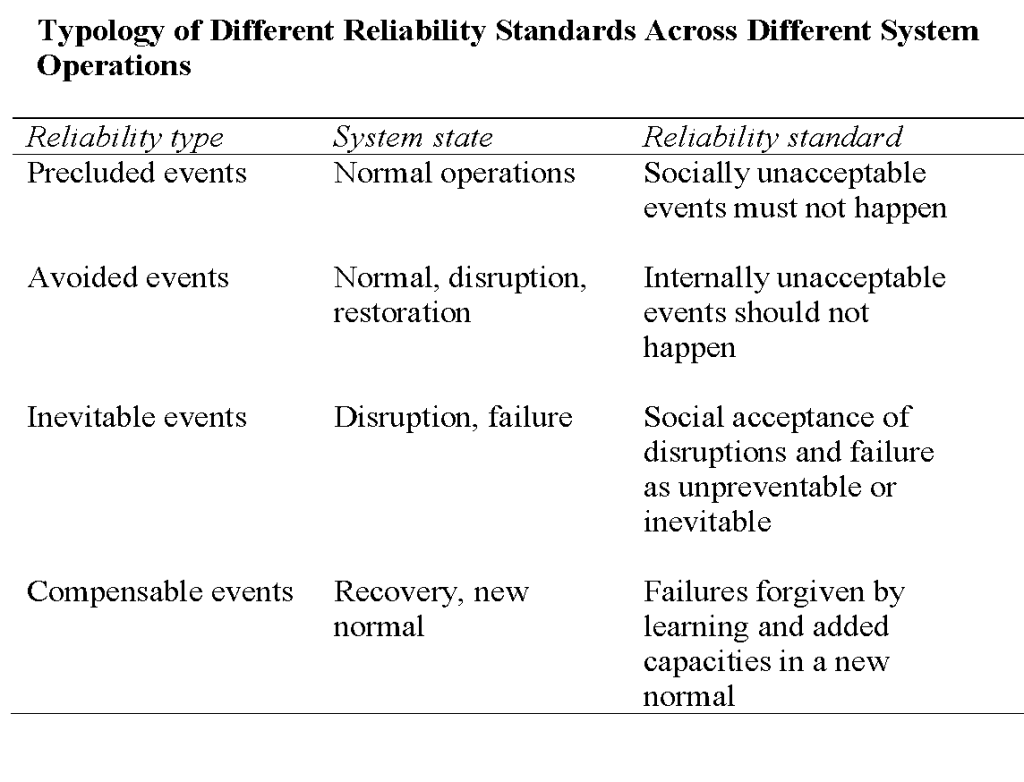
1. Infrastructure performance standards and stages (states) of operation.
Our research identified the following four performance standards to which critical infrastructures managed in real time (there could of course be more):
Note that standards are intimately tied to the frequency of different stages of operation in the critical infrastructure: normal or routine operations, sometimes temporarily disrupted and then restored back, at other times tripping over into outright system failure, thereafter responded to urgently as an emergency and eventually to be recovered, from which a new normal may evolve systemwide (though no guarantees!).
In a world of few disruptions let alone outright system failures, normal operations (which are not static!) dominated and were often associated with a precluded events standard of high reliability, i.e., certain events like loss of containment at nuclear reactors, must never happen (think also of those faraway days of the integrated energy utility, where generation could determine transmission and then distribution).
But it may no longer be possible to preclude such events (especially in the infrastructures which this infrastructure depends upon), such that an avoided events standard is adopted. Some dreaded events, on the other hand, may be treated as inevitably creating major infrastructure disruptions or failures (e.g., earthquakes in Indonesia) or can be compensated for in some major safety improvements afterwards (as after Three-Mile Island). (This “compensatory reliability” standard, needless to say, reduces social pressures for a precluded or avoided event standards.)
The take-away point is that the risks and resiliencies to be managed look very different given the standard to be operated to and the stage(s) of operations the (variably interconnected) infrastructure finds itself today.
2. Risks follow from performance standards being managed to.
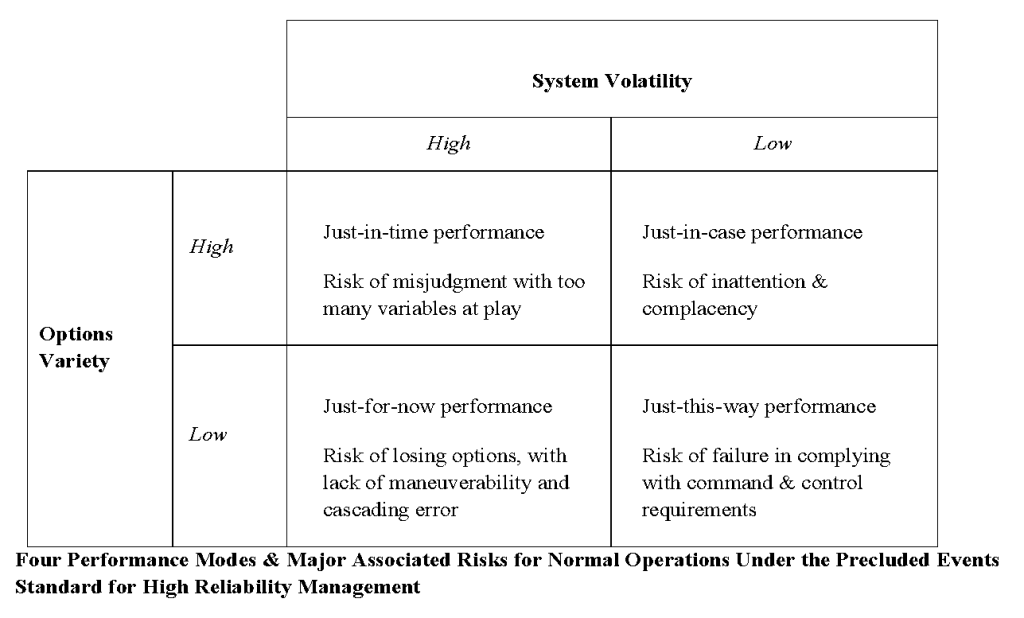
Below are findings from our research which identified different systemwide risks faced by the central control of a major energy infrastructure, operating under a precluded events standard and depending on the volatility of its task environment and the options available to respond to that volatility:
Under the precluded events standard that the transmission infrastructure must never island, we observed four performance modes of normal operations, ranging from anticipatory exploration of options (just in case) when operations are more routine and many control strategies and options are available, to a real-time (just in time) improvisation of options and strategies when task conditions are unstable (i.e., they are unpredictable or uncontrollable even if predicted). Operators may have to operate temporarily in a high-risk mode (just for now) when system instability is high and options are few.
They may also be able, in emergencies when options have dwindled, to impose onto grid participants a single emergency scenario (just this way) in order to stabilize a situation. These alternative but interrelated performance modes are part of an overall requisite variety of responses needed to match the full range of input variance that operators can encounter in their systems, all for the purposes of reliable output management.
But each performance mode has its own dominant risk from the control room perspective. According to our interviewees, the big risk in just-in-case performance is that someone in the control center is not paying attention to and being complacent with respect to sudden or emerging changes in system volatility or network options variety. “What you want to do is avoid complacency,” a senior utilities control room official said about his operators. When it comes to just-in-time performance, the risk is misjudgment by control operators with so many balls in the air at one time. The great risk in just-this-way performance is that not everyone who must comply will comply with the emergency.
Last but decidedly not least, just-for-now performance (“just keep that online right now!”) is the most unstable performance mode of the four and the one control operators and managers want most to avoid or exit from as soon as they can. Here the risk is tunneling into a course of action without escape alternatives. What you do now could increase the risks later (in effect, options and volatility are no longer independent dimensions). Speaking of a major vessel collision and spill, a support person in the Coast Guard Vessel Traffic Service noted, “The closer it [a large ship] got to the bridge, the more the options dwindled.” In effect, the few options remaining may be such that to use one risks increasing volatility elsewhere in the infrastructure, if not in the other infrastructures dependent upon it.
Note the major policy and management implication of just-for-now performance. If the real time challenge is to increase options and/or reduce task volatility, the most efficient strategy is to adopt and modify better practices already used by like operators in like just-for-now situations. Crudely put, if they are better able to jump a bar of politics, dollars and jerks like yours, then start from their practices.
The take-away point here is that these are systemwidemanagement risks of key importance to the infrastructure’s real-time operators.They are NOT the specific risks of corroding pipes underground, or underwater seepage of flood levees, or the risks of climate change. Of course, the latter can and do affect task volatility and/or options availability, which however are important precisely when they affect and/or shift the more important systemwide management risks identified above. (Note that the above systemwide risks were observed for infrastructures with central control rooms operating under the avoided events standard.)
3. Types of system resilience vary by stage of infrastructure operations.
Our research identified four specific types of resilience for reliability management at the system level, each varying by stage (or state) of system operations discussed above:
real-time system operators adjusting back to within official or unofficial reliability bandwidths to continue normal operations (precursor resilience);
Restoration from disrupted operations (temporary loss of service) back to normal operations by these real-time operators (restoration resilience);
immediate emergency response (as its own kind of resilience) after system failure but often involving others different from system’s reliability professionals; and
recovery of the system to a “new normal” by real-time infrastructure operators along with others (recovery resilience)
These four specific types of resilience for reliability management constitute overall systemwide resilience, summarized together as “the system’s capability in the face of its reliability mandates to withstand the downsides of uncertainty and complexity as well as exploit the upsides of new possibilities and opportunities—sometimes called “affordances”—that emerge in real time.”
Please note the implications of this classification. Not only are normal operations NOT static or uniform, resilience options differ depending on whether or not the large sociotechnical system is in normal operations versus disrupted operations versus failed operations versus recovered operations.
Resilience, here, is not a single property of the system to be turned on or off as and when needed. It is not one stable portfolio called “process variance” from which to choose this or that already-existing option depending on the stage of operations. (Again, improvisation in the face of unexpected contingencies and assembly of options just in time are instead found, though never guaranteed.)
Note also that it’s not inevitable that the failed system recovers to a new normal. It is crucial, nevertheless, to distinguish recovery from the new normal. To outsiders, it may look like some of today’s sociotechnical systems are in unending recovery, constantly trying to catch up with one disaster after another.
The reality for real-time system operators however, may be that the system is already at a new normal, operating to a standard of reliability different than the outsiders might think. (One thinks immediately of new media platforms, e.g.: Is the capacity to achieve reliable normal operations in digital platforms—not by precluding or avoiding certain events but by adapting to electronic component failure most anywhere and most all of the time—a key skill set of software professionals and their wraparound support in critical infrastructures for emergency management?)
4. The special importance of inter-infrastructural connectivity during infrastructure failure, immediate emergency response & initial service restoration, and longer-term recovery.
What were latent interconnections between and among infrastructures before a disaster often become manifestly evident in that disaster. The earthquake hits, underground water mains break, leakage spreads first out of sight, and then above-ground sections of the road collapse.
The principal management elements of interest in these changes from latent to manifest infrastructural interconnectivity are: the types of interconnectivity configurations among network elements (sequential, reciprocal, mediated and pooled between and among infrastructures); the shifts in configurations during failure, response and recovery states (e.g., the road now becomes a firebreak); and the joint improvisations involving more than one infrastructures because the respective control variables of these systems are shared or interconnected (e.g., river navigation, town water supplies, and regional hydro-power depend on changes in related dam water releases and pressures). Here too we see that resiliencies triggered in failure, response and recovery must themselves be differentiated when it comes to practice and interventions.
IV
A final point (for an already overly long blog entry). Much of the above is centered around on-the-ground practices (for infrastructure management and operation in particular). This is because I am a practicing policy analyst by profession–although it might seem a small point to you.
Yet it is a very big point, if your profession or discipline gives pride of place to human values, beliefs and attitudes as determinants of really-existing behavior. I come from a literature which repeatedly finds a low statistical correlation between why people say they act and how they actually act. I come from a profession that constantly asks not what is planned or designed but how it is implemented and operated, full of contingent events, situations and context, notwithstanding the power asymmetries attributed to system operations by outsiders.
In more general and summary terms, the logic of capitalist accumulation has had a clear impact on infrastructure operations over time; the logic of requisite variety has now a clear albeit contingent impact on infrastructure operations in the Anthropocene. The difference between the two is due in large part to shifting infrastructural interconnectivities: then, now and ahead.
NB. The above has been spliced and sutured together from a number of previous publications and blogs. The original research for the above was undertaken and co-authored with my colleague Paul R. Schulman. As such, I am responsible for any misleading simplifications or hydraulic interpretations that have crept into the preceding.
So many Debbie Downers out there. No sooner than the author says societal decay can be overgeneralized, we’re off and running with how capitalism leads to even greater decay in the life-world. More, decay is over-determined. If not capitalism, it still comes with these earthly bodies and infrastructures of ours. That such thinking deoxygenates policy and management should not be surprising.
What to do? If we don’t like the language game around decay, Wittgenstein tells us: Get another one. Which is what many do with talk of renewal and such. Others insist that terms like decay, renewal and infrastructures need to be jettisoned in favor of different cosmologies (that is, altogether different life-worlds). But whether appealing to different language games or different cosmologies, we again place ourselves further from current understandings of policy relevance in the hope that whatever the ensuing change it’s a big-T transformation rendering current disputes moot.
The problem with big-T transformations is that the stories we tell to achieve these ends are always in excess of the ends. That is, relations, social and otherwise, need to be (re)woven or repaired via stories we tell if we are to be transformative. As one author put it, something like “resocialization through narrative” is sought more so than–or at least before–big-T transformation.
The reparative function of the stories we tell our people is not much discussed–especially as it implies that the policy narratives used to underwrite decisionmaking in the face of uncertainty, complexity, conflict and unfinished business are also reparative in ways under-acknowledged. (For example, metanarratives that demonstrate how conflicting positions can hold at the same time are first and foremost reparative.) It’s repair under unpredictable conditions–not decay as the certainty that can’t be changed–that is the object of analysis when policy and management relevancies matter now and in the next steps ahead.
Sources.
On decay, see: N.M. Küttel (2026). “From extraction to afterlife: toward a political materialism of urban ruins.” Urban Geography (accessed online at https://doi.org/10.1080/02723638.2026.2676282)
On “resocialization through narrative” see: A. Gefen (2024 [2017]) Repair the World: French Literature in the Twenty-First Century, translated from the French by Tegan Raleigh, Volume 28 of Culture & Conflict, Walter de Gruyter GmbH, Berlin/Boston
This photograph shows what were formerly residential lots later abandoned and emptied in a part of Detroit, Michigan:
According to an expert, these instances require us “to think about innovative and productive ways to manage and transform vacancy for long-term sustainability” not only in Detroit but in like areas (Dr. Toni Griffin, Professor in the Practice of Urban Planning at the Harvard Graduate School of Design commenting on the presentation, “Last House on the Block: Black Homeowners, White Homesteaders, and Failed Gentrification in Detroit,” accessed online at https://www.youtube.com/watch?v=umqU1xj5yPA).
I want to take up Dr. Griffin’s challenge and recast what you see (and don’t see) in that picture in equally policy relevant ways for “low-density” (mixed-use) grasslands in parts of Africa with which I am familiar.
I
Let’s start with the obvious points raised by the above photo.
In reality, the space bounded by the two edge sidewalks isn’t vacant. What you don’t see are not just the biophysical activities on the ground and below, you also don’t see the socioeconomic relations that crisscross the space even now. For all I know, new construction could be happening the day after tomorrow or the lot was the site of a crafts fair a week before the photo was taken.
Far-fetched, you say? Consider the description of one such project on one Detroit lot:
The Heidelberg Project, founded by Tyree Guyton in the mid-1980s, is perhaps Detroit’s most well-known – and controversially discussed – outdoor art environment. Spanning a block of vacant houses and lots, the project comprises a dense assemblage of discarded objects. . . (accessed online athttps://www.tandfonline.com/doi/full/10.1080/02723638.2026.2676282)
And yet, the blisteringly obvious in the photo is that the space is NOT vacant. It’s full of repurposed objects (about which, by the way, you know little unless described further). Such however is the powerful imaginary that “vacant” still carries with it.
II
So what?
Just what does this mean for “the management of vacancy,” be it in peri-urban Detroit or low-density (mixed use) rangelands of East or Southern Africa?
It means we have to think more granularly than snapshot reality could ever permit.
For example, what if the former settler ranches in parts of Africa now subject to the mixed (arable, horticultural, animal) uses are in fact the result of that having, as Dr. Griffin put it, “to think about innovative and productive ways to manage and transform [really-existing] vacancy“?
In Detroit, white urban farmers have moved into some of these depopulated neighborhoods. In Africa examples, the racial demographics are largely reversed, but the analogy remains strong: Just as this urban farming has been mistakenly criticized as failed gentrification (the first wave of Detroit urban farmers never saw themselves as gentrifiers), so too arable and agro-pastoral farmers are mistakenly criticized for falling short of specialized livestock rearing or crop production thought to be more suitable by governments and their experts.
More important (for me) the policy implications differ depending on the benchmark against which to assess really-existing use variety on the ground. Is it any wonder that “gentrification”, like “dryland livestock ranching”, have no agreed-upon definitions? (Academics are still debating the causes and consequences of gentrification here in the US.) Is it any wonder then that both concepts are never so fiercely argued over as when they’re offered up as “solutions”? Ideal types are just another version of blueprint development.
Thornton lowered his voice. “You see, dearest, it’s been a sea-change since you abandoned the humanities and went off to that professional school of yours. You wouldn’t believe the committees the chancellor puts me on! Of course my lips are sealed about deliberations. Sealed, sealed, sealed. Ask no more, Peter. Don’t even try!”
“Thornton, this is not going to be your usual wicked and droll, is it?” Peter responded.
“Moi? Everything I’m about to say is entirely fair, considering the principals involved. Though not everything learned made it into my final report to the chancellor,” added Thornton.
“I have to start with the background. One of the first things the new chancellor did was to establish the All Campus Organizing Council. All-COC, which I regret to say it is not, has many mandates, but you need only know that it fosters all manner of taskforces. I chaired what is called the interdisciplinary team, of whose acronym I also need say no more. It was milked for an interdisciplinary seminar in that department, a cross-disciplinary conference in another department, a trans-disciplinary workshop off campus.
“Now, from time to time it was my sore duty to attend the events we sponsor. Some did betray a whisper of humor, but most devolved into a discussion about ethics, and you just know a field is going absolutely nowhere, when the only thing they have to discuss is ethics!
“Well, here I am at a seminar in the College of Agriculture, Resources and the Environment. That’s CARE to you, which it most emphatically does not. Peter, dear, you must remember the college? It produced the stay-soft (all-mush) peach, the BetterLife™ (Bet-her-life!) household insect sprays, and the workerless irrigation technologies (or WITless to its critics). If you believe the CARE reports, a dollar of research leads to a $2.50 return in agricultural productivity, blah blah market share blah blah.
“What this research actually means, of course, is the further immiseration of farmworkers, the erasure of the family farm hitherto known to humanity, and the concentration of productive wealth into multinational corporations. Yes, yes, the tiresome litany. However, small blessings being what they are, the press sniffed some of what was going on, the mediaship went into its usual brownian motion, the legislature rumbled, a court case was decided, and, lo, CARE found itself more caring.
“One consequence was my team was asked to come through the front-door and sponsor the Dean’s Seminar Series, ‘What are natural resources?’ The idea was a simple one, as you might expect. Whatever, I find myself at a seminar titled ‘What are natural resources? The perspective of a humane biotechnologist.” The boredom was palpable. Four people in the room. Finally, I asked the most perfectly obvious question, absolutely no malice intended Peter, so I put forward, with the obligatory outsider preamble of not being a scientist, “What about agricultural biotechnology is natural?” I mean, it is thelr title! So the presenter looks at me, pauses for that longest moment, and says: “But, what’s more natural than a gene?”
“Well, let me tell you Peter you needn’t be a slave to history for your eyes to widen, right? I am feeling very good about myself these days, and just when I’m thinking about having myself cloned, these Mengeles-in-waiting are talking as if they’re ready to take away the very molecules that make me interesting. Well, I mean, really. I knew then these people needed watching.
“So, when out of nowhere, the chancellor asks me to chair the very hush-hush committee on the scandals involving the College’s new dean, I accepted with utmost alacrity.
I now must introduce the College’s dean to you, Dean Trumplethinskin. You may have met him when you were there, Peter. He was just a senior faculty member then, one of those kinds of business school types you’re supposed to get used to. He has always had a deplorable reputation for being abrasive in social gatherings and lacking skills for polite company. ‘Grab ‘em by the pussy’ he’d say by way of motivating people.”
Peter snapped his fingers. “Of course! My God, not the Trumplethinskin?’ Thornton nodded grimly, adding for good measure: “He’s at a colleague’s party, she hands him his drink, he sips, his face goes sour, she asks what’s wrong, he says, ‘This drink is like screwing in a canoe–fuckin near water,’ and then turns away.”
“It all started about ten years ago,” Thornton contined. “Trumplethinskin is recruited to our campus’s league of nation states as the first incumbent of the Walter P. Grapefruit Chair in Anti-Communist Political Economy. It turns out he also arrives just as the start of the CARE’s reorganization wars. The old dean tried to create a Department of Social Studies by merging the College’s Department of Agricultural Economics with College units on park and nutritional sociology. It was Trumplethinskin’s abrasiveness that saved their day. ‘You can’t do that!,’ he shouted. ‘They’re economists, for Christ’s sake, not social scientists! Our journals are peer-reviewed. When was the last time any of them were published in Mathematica?’
“The reorganization wars left a bad taste for most everyone. Trumplethinskin’s predecessor fast became the most reviled man in CARE. Programs had suddenly been branded ‘environment.’ Muffled screams for ‘evolution, not revolution’ were heard in the hallways. Faculty meetings would find social scientists hectoring insecticide faculty, ‘Well, at least our research doesn’t kill farmworkers!’ CARE was not a happy place. The old dean retreated to his office. He retired. ‘I leave for the best job in the world,’ he said at his going-away party: ‘I’m going to be a former dean!’ Those there said he almost looked young again.
“During all that time, Trumplethinskin relished less and less the well-feathered eyrie of his departmental chair. He had reached a stage where it was time to move on, do something different, make more money, not more articles on the role of hotel schools in agriculture. What better, then, than the deanship?
“The search for the new dean was speedy. The other candidates were a cultural historian, whose book, The Social Construction of Nature, was well-received by her two colleagues; a bioengineer, who didn’t own a biotech company and thus had no respect among his peers; and a well-known political scientist who always thought it best to conclude, rather than start, his publications with some variant of ‘We’re still not asking the right questions. . .’ Frankly Trumplethinskin could have crowned himself dean.
“Once leader of the pack, the new Dean’s first task was to take ‘reorganization’ to new depths. He drove though the privatization of the CARE’s agricultural extension funds into an online digital platform, weCARE2.edu. He hired a consultant from his own outside firm who recommends that, yes the new Department of Life Sciences should remain, but should be decentralized into divisions that ‘more matched the unique distribution of faculty expertise, core competencies and disciplinary fields,’ namely, the original private sector focus on insecticides, agricultural technology, industrial forestry, and farm management.
The dereorganization is then implemented, which meant–of course!–the Dean’s office had also to become a profit center. Which–of course!–made Trumplethinskin far too reckless. Which in turn led to the scandals I ended up investigating. . .”
Thornton paused, took another sip, and actually looked forward to what came next.
Read the finer essays of George Steiner, John Berger, Adam Phillips—or if you will, Helen Vendler, Marguerite Yourcenar, Jane Hirshfield, Lydia Davis—and you encounter in each an analytic sensibility, sui generis. No need here for a shared point of departure to understanding complexity’s implications for public and private.
Indeed, there are times when the very different analytic sensibilities posed by the poetry of A.R. Ammons, Jorie Graham, Robert Lowell and (yes, even) J.H. Prynne achieve actual policy relevance. I say this knowing it’s outrageous to demand policy relevance from poets. But I suggest you also can read them and others that way.
Ammons and regulation
Policy types fasten to knowledge as a Good Thing in the sense that, on net, more information is better in a world where information is power. Over an array of accounts, A.R. Ammons insists that the less information I have, the better off I am—not all the time, but when so, then importantly so. (To be clear, he is not talking about “ignorance as bliss.”)
For those working in policy and management, how could it be that “the less we know, the more we gain”? In order to make our exercise here more interesting, what would that mean when it comes to the heavy machinery called official regulation? Is there something here about the value of foregrounding inexperience—having less “knowledge”—as a way of adding purchase to rethinking government regulation?
–By way of an answer, jump into the hard part—Ammons’s poem, “Offset,” in its entirety:
Losing information he rose gaining view till at total loss gain was extreme: extreme & invisible: the eye seeing nothing lost its separation: self-song (that is a mere motion) fanned out into failing swirls slowed & became continuum.
You may want to reread the poem once more.
Part of what Ammons seems to be saying is that by losing information—the bits and pieces that make up “you”—you gain by becoming less separate, your bits and pieces slow down, fan out, spread into a vital whole. We empty our minds so as to attend to what matters—emptying the eye to have the I.
So what? How, though, is this different from ignorance is bliss or, less pejoratively, seeking to know only what you need to know?
–When pressed by an interviewer, Ammons’s response illuminates much about how knowing less is gaining more: “I’m always feeling, whatever I’m saying, that I don’t really believe it, and that maybe in the next sentence I’ll get it right, but I never do”.
Imagine policymakers and regulators, when pressed, recognizing that not getting it right today places them at the start of tomorrow’s policymaking—not its end but its revision of even the categories of “policymaking” and “regulation.” Ammons, if I understand him, is insisting that in the compulsion to “get it right the next time around” there is more importantly a next time to make it better. Again, not just to make a specific regulation better, but to revise what we mean by “regulating.”
To recast (revise, redescribe, rescript, recalibrate) the categories of knowing and not-knowing is to make room for—empty your mind for—resituating the cognitive limits of “regulation.”
Jorie Graham and the climate emergency
No one could accuse Jorie Graham of being hopeful about the climate emergency. There is not a scintilla, not a homeopathic whiff, of environmental optimism, techno-social-otherwise, in the poetry I’ve read of hers.
Which poses my challenge: Can we readers nevertheless find something to move forward with from her recent poetry? Is there some thing that I can see of possible use in my own response to the climate emergency?
In answer, consider the lines from her book, Sea Change:
the last river we know loses its form, widens as if a foot were lifted from the dancefloor but not put down again, ever, so that it's not a dance-step, no, more like an amputation where the step just disappears, midair, although also the rest of the body is missing, beware of your past, there is a fiery apple in the orchard, the coal in the under- ground is bursting with sunlight, inquire no further it says. . .
There’s that tumbling out and after-wash of words and the turns of phrase. Witness though how they bounce off and back from, in this case, the hard left-side margins and that right-side enjambment.
Some might call her rush of words a compulsion to continue but for someone with my background and training, it’s difficult not to see this as resilience-being-performed as the dark messages bounce back or forth. Following Graham, we readers make resilience happen.
Robert Lowell and alertness
“Design” too often assumes one can macro-design the micro. Anyone who has tried to implement as planned knows how plug-and-play designs don’t work in complex policy and management, as contingency in the form of situation, context and even invariably get in the way. (For my part, it’s difficult to imagine two words scarier in the English language than business schools’ “designing leadership.”)
To see how this matters for policy and management, consider a late poem of Robert Lowell, “Notice,” and a gloss on it by Helen Vendler, the late literary critic. Here’s the poem in its entirety, centering around Lowell’s leaving an asylum after a manic-depressive episode:
Notice
The resident doctor said, “We are not deep in ideas, imagination or enthusiasm – how can we help you?” I asked, “These days of only poems and depression – what can I do with them? Will they help me to notice what I cannot bear to look at?”
The doctor is forgotten now like a friend’s wife’s maiden-name. I am free to ride elbow to elbow on the rush-hour train and copy on the back of a letter, as if alone: “When the trees close branches and redden, their winter skeletons are hard to find—” to know after long rest and twenty miles of outlying city that the much-heralded spring is here, and say, “Is this what you would call a blossom?” Then home – I can walk it blindfold. But we must notice – we are designed for the moment.
I take up Vendler’s gloss when she turns to Lowell’s last line:
In becoming conscious of his recovery by becoming aware, literally moment by moment, of his new capacities for the most ordinary actions of life, the poet sees that ‘we are designed for the moment’—that our consciousness chiefly functions moment by moment, action by action, realization by realization. Biologically, ‘we are designed for the moment’ of noticing.
For my part, what Lowell is doing in the last two lines is also revisiting the second line, “We are not deep in ideas, imagination or enthusiasm” and making this point: The designs put upon us by ideas and enthusiasms differ from the noticing designed into us in at least one major respect: We notice the ideas-that-design because noticing is not an idea. It’s an alertness. It is a kind of watchfulness—“Is this what you would call a blossom?” It’s the analytic sensibility that saves us from those other designs.
An application of J.H. Prynnefor policy relevance
I’m new to Prynne’s poetry and haven’t yet gotten a knack for how to read and interpret the more recent ones. This means I, more than not, don’t have a clue about the author’s intention (which shouldn’t matter anyway, so some say).
Which also means I get to interpret his lines far more in my own terms than others might like. Take the following stanza:
Indefatigable, certainly impracticable, chronic unretractable, spree; indistinguishable epiphenomenal dink-di flunk, rhetic; insurmountable, unaccountable, incommensurate, providentially, turn up your nose as we suppose, environmentalism, fiddle-de-dee.
Whatever this means to others, to me it’s a clear example of how many advocates for and against environmentalism overstate their case through argument by adjective and adverb.
Or consider a different stanza:
Casting out terror leaves a vacant spot, your care-free jubilation to out-jest these heart-struck injuries, mimic new disasters; they crowd like fresh battalions, eager spies trying our patience, good out-runs the best.
I interpret “casting out terror leaves a vacant spot” to mean that once we lose widespread social dread over large technical disasters like nuclear plant explosions, we vacate any notion of reliably managing such extremely hazardous systems.
There are, of course, those who celebrate such an eventuality–think of them as eager spies for the other side. But the loss of reliable infrastructures also does injury and harm to many more other people. Indeed, new disasters arise (imagine the effects of a society no longer fearful of jet planes dropping from the air like flies). The new disasters would “crowd like fresh battalions” and “try our patience” by way of increased calls for different policy and management interventions.
But note Prynne’s “good out-runs the best” as a consequence. No problem. For many trained in policy analysis, such as myself, the best is the enemy of the good. That is, better to have good enough when the best is not achievable (which would be to prevent disasters in the first place). What then is good enough in having a disaster? Ironically, disasters are a way to get rid of legacy infrastructures and components that, under other circumstances, one is precluded from doing so because of existing regulation and law. These would be suspended during the emergency.
My reading too far-stretched? In my view, Prynne’s words read as if they are the only ones left legible on the surface of a thick, many-layered palimpsest. A good deal has been effaced or scored away below and down. My point is that those very same words are also left visible on policy palimpsests with which I am familiar.