I
Say, you are a policy analyst tasked by your agency to produce a desk-top report answering, “What’s the risk of flooding in downtown Helsinki due to changing sea levels, storm surges, and inland run-off because of climate change in the next decade or two?”
You look first for existing probability and risk estimates, and not just in official documents but also in the grey literature of engineering and consultants’ reports, including modeling and simulation findings. Unsurprisingly, given the fragmentary findings, you recommend, among other priorities, increasing the resilience of existing flood management and emergency management infrastructures to better respond to the unpredictabilities ahead.
In this iteration, you–and we–start with risk and work our way to calling for more resilience as part of the solution portfolio, especially for (though not exclusively) the critical infrastructures directly involved in flood and emergency response.
I argue that it’s a very misleading approach to start out with considerations of risk and resilience and end up with implications for infrastructure change. The analysis looks very different when you begin with the existing infrastructures, how they are actually managed for the physical systems actually operated on the ground, and then look for the risks (and resiliencies) that come with managing the sociotechnical system(s) that way or those ways, now that changing climate conditions have been posed as above.
II
So return to the starting question: “What’s the risk of flooding in downtown Helsinki due to changing sea levels, storm surges, and inland run-off because of climate change in the next decade or two?”
Questions of risk/resilience are only raised after answering two logically and empirically prior questions, if infrastructures start the analysis. First the analyst has to answer:
Q1. What are the infrastructure systems of concern and how are they operated and managed on the ground? It’s of course not just flooding and emergency management infrastructures you are concerned with, but lifeline infrastructures interconnected with the two, not least of which are energy (e.g., electricity), transportation, telecommunications and water supplies (including wastewater). Even more important is the focus on how these systems operate in real time, irrespective of how they are supposed to operate because of design, regulation or technology blueprints.
Q2. What are the standards of reliability and safety to which these systems are actually managed (e.g., if it is managed to a precluded-event standard, what are the events that must never happen—for instance, urban water supplies should not be contaminated by cryptosporidium or LSD, the electricity grid should not island, airplanes should not drop from the sky all over the place)?
Once Q1 and Q2 have been answered and only then does our analyst ask and answer:
Q3. What then are the risks and resiliencies to be managed that follow from meeting these standards for those systems as they operate in real time and over time on the ground?
Of course, much of the above (as below) is compressed. Still, it’s safe to say much of the critical infrastructure literature starts with a version of Q3—the risks to be managed (let alone other unpredictabilities)—without answering the two prior questions. Ignoring questions about operational boundaries and standards and starting instead with the third serves to import economic and engineering assumptions about optimal reliability into the analysis that are not empirically correct. When spatial boundaries and reliability standards are not addressed first, it is too easy to reduce “management” to an altogether unrealistic choice: Do I, the decisionmaker, take on more or less risk in light of my optimality criteria? That is one huge way operational mismanagement can and has happened.
III
Now let’s unpack Q2 and Q3 in more useful detail: What are the different standards of reliability and safety? and What are the different risks and resiliencies that follow from these respective standards? What, then, about important interconnections?
1. Infrastructure performance standards and stages (states) of operation.
Our research identified the following four performance standards to which critical infrastructures managed in real time (there could of course be more):
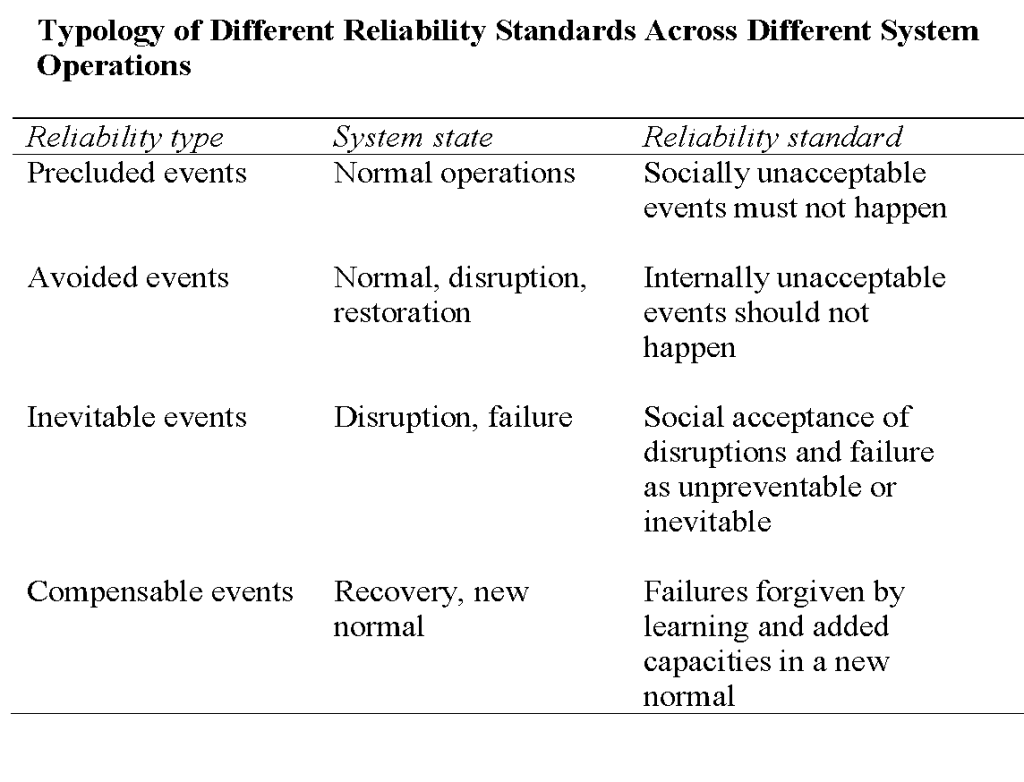
Note that standards are intimately tied to the frequency of different stages of operation in the critical infrastructure: normal or routine operations, sometimes temporarily disrupted and then restored back, at other times tripping over into outright system failure, thereafter responded to urgently as an emergency and eventually to be recovered, from which a new normal may evolve systemwide (though no guarantees!).
In a world of few disruptions let alone outright system failures, normal operations (which are not static!) dominated and were often associated with a precluded events standard of high reliability, i.e., certain events like loss of containment at nuclear reactors, must never happen (think also of those faraway days of the integrated energy utility, where generation could determine transmission and then distribution).
But it may no longer be possible to preclude such events (especially in the infrastructures which this infrastructure depends upon), such that an avoided events standard is adopted. Some dreaded events, on the other hand, may be treated as inevitably creating major infrastructure disruptions or failures (e.g., earthquakes in Indonesia) or can be compensated for in some major safety improvements afterwards (as after Three-Mile Island). (This “compensatory reliability” standard, needless to say, reduces social pressures for a precluded or avoided event standards.)
The take-away point is that the risks and resiliencies to be managed look very different given the standard to be operated to and the stage(s) of operations the (variably interconnected) infrastructure finds itself today.
2. Risks follow from performance standards being managed to.
Below are findings from our research which identified different systemwide risks faced by the central control of a major energy infrastructure, operating under a precluded events standard and depending on the volatility of its task environment and the options available to respond to that volatility:
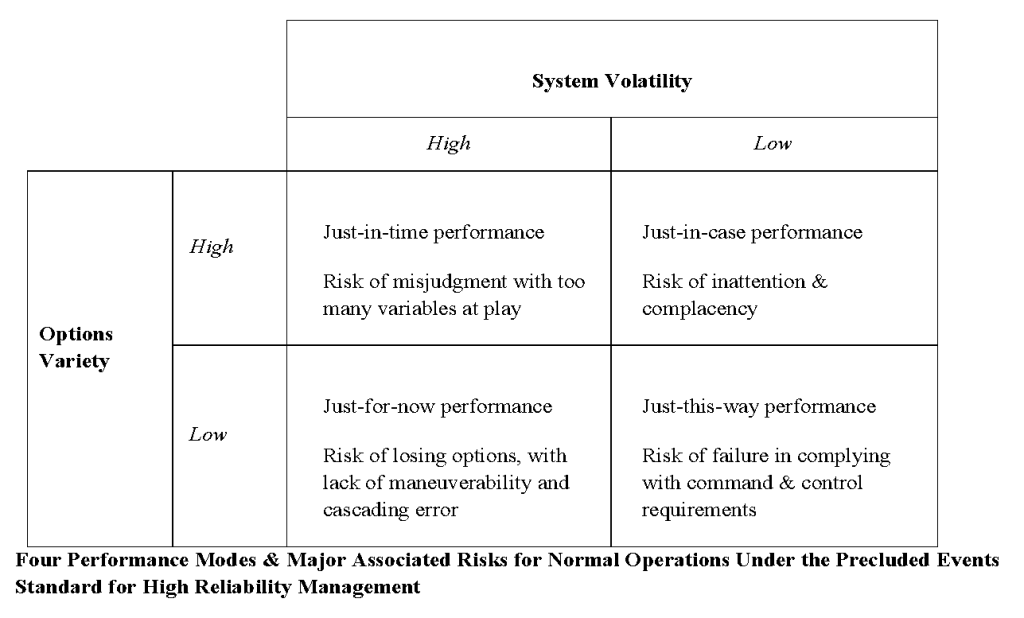
Under the precluded events standard that the transmission infrastructure must never island, we observed four performance modes of normal operations, ranging from anticipatory exploration of options (just in case) when operations are more routine and many control strategies and options are available, to a real-time (just in time) improvisation of options and strategies when task conditions are unstable (i.e., they are unpredictable or uncontrollable even if predicted). Operators may have to operate temporarily in a high-risk mode (just for now) when system instability is high and options are few.
They may also be able, in emergencies when options have dwindled, to impose onto grid participants a single emergency scenario (just this way) in order to stabilize a situation. These alternative but interrelated performance modes are part of an overall requisite variety of responses needed to match the full range of input variance that operators can encounter in their systems, all for the purposes of reliable output management.
But each performance mode has its own dominant risk from the control room perspective. According to our interviewees, the big risk in just-in-case performance is that someone in the control center is not paying attention to and being complacent with respect to sudden or emerging changes in system volatility or network options variety. “What you want to do is avoid complacency,” a senior utilities control room official said about his operators. When it comes to just-in-time performance, the risk is misjudgment by control operators with so many balls in the air at one time. The great risk in just-this-way performance is that not everyone who must comply will comply with the emergency.
Last but decidedly not least, just-for-now performance (“just keep that online right now!”) is the most unstable performance mode of the four and the one control operators and managers want most to avoid or exit from as soon as they can. Here the risk is tunneling into a course of action without escape alternatives. What you do now could increase the risks later (in effect, options and volatility are no longer independent dimensions). Speaking of a major vessel collision and spill, a support person in the Coast Guard Vessel Traffic Service noted, “The closer it [a large ship] got to the bridge, the more the options dwindled.” In effect, the few options remaining may be such that to use one risks increasing volatility elsewhere in the infrastructure, if not in the other infrastructures dependent upon it.
Note the major policy and management implication of just-for-now performance. If the real time challenge is to increase options and/or reduce task volatility, the most efficient strategy is to adopt and modify better practices already used by like operators in like just-for-now situations. Crudely put, if they are better able to jump a bar of politics, dollars and jerks like yours, then start from their practices.
The take-away point here is that these are systemwide management risks of key importance to the infrastructure’s real-time operators.They are NOT the specific risks of corroding pipes underground, or underwater seepage of flood levees, or the risks of climate change. Of course, the latter can and do affect task volatility and/or options availability, which however are important precisely when they affect and/or shift the more important systemwide management risks identified above. (Note that the above systemwide risks were observed for infrastructures with central control rooms operating under the avoided events standard.)
3. Types of system resilience vary by stage of infrastructure operations.
Our research identified four specific types of resilience for reliability management at the system level, each varying by stage (or state) of system operations discussed above:
- real-time system operators adjusting back to within official or unofficial reliability bandwidths to continue normal operations (precursor resilience);
- Restoration from disrupted operations (temporary loss of service) back to normal operations by these real-time operators (restoration resilience);
- immediate emergency response (as its own kind of resilience) after system failure but often involving others different from system’s reliability professionals; and
- recovery of the system to a “new normal” by real-time infrastructure operators along with others (recovery resilience)
These four specific types of resilience for reliability management constitute overall systemwide resilience, summarized together as “the system’s capability in the face of its reliability mandates to withstand the downsides of uncertainty and complexity as well as exploit the upsides of new possibilities and opportunities—sometimes called “affordances”—that emerge in real time.”
Please note the implications of this classification. Not only are normal operations NOT static or uniform, resilience options differ depending on whether or not the large sociotechnical system is in normal operations versus disrupted operations versus failed operations versus recovered operations.
Resilience, here, is not a single property of the system to be turned on or off as and when needed. It is not one stable portfolio called “process variance” from which to choose this or that already-existing option depending on the stage of operations. (Again, improvisation in the face of unexpected contingencies and assembly of options just in time are instead found, though never guaranteed.)
Note also that it’s not inevitable that the failed system recovers to a new normal. It is crucial, nevertheless, to distinguish recovery from the new normal. To outsiders, it may look like some of today’s sociotechnical systems are in unending recovery, constantly trying to catch up with one disaster after another.
The reality for real-time system operators however, may be that the system is already at a new normal, operating to a standard of reliability different than the outsiders might think. (One thinks immediately of new media platforms, e.g.: Is the capacity to achieve reliable normal operations in digital platforms—not by precluding or avoiding certain events but by adapting to electronic component failure most anywhere and most all of the time—a key skill set of software professionals and their wraparound support in critical infrastructures for emergency management?)
4. The special importance of inter-infrastructural connectivity during infrastructure failure, immediate emergency response & initial service restoration, and longer-term recovery.
What were latent interconnections between and among infrastructures before a disaster often become manifestly evident in that disaster. The earthquake hits, underground water mains break, leakage spreads first out of sight, and then above-ground sections of the road collapse.
The principal management elements of interest in these changes from latent to manifest infrastructural interconnectivity are: the types of interconnectivity configurations among network elements (sequential, reciprocal, mediated and pooled between and among infrastructures); the shifts in configurations during failure, response and recovery states (e.g., the road now becomes a firebreak); and the joint improvisations involving more than one infrastructures because the respective control variables of these systems are shared or interconnected (e.g., river navigation, town water supplies, and regional hydro-power depend on changes in related dam water releases and pressures). Here too we see that resiliencies triggered in failure, response and recovery must themselves be differentiated when it comes to practice and interventions.
IV
A final point (for an already overly long blog entry). Much of the above is centered around on-the-ground practices (for infrastructure management and operation in particular). This is because I am a practicing policy analyst by profession–although it might seem a small point to you.
Yet it is a very big point, if your profession or discipline gives pride of place to human values, beliefs and attitudes as determinants of really-existing behavior. I come from a literature which repeatedly finds a low statistical correlation between why people say they act and how they actually act. I come from a profession that constantly asks not what is planned or designed but how it is implemented and operated, full of contingent events, situations and context, notwithstanding the power asymmetries attributed to system operations by outsiders.
In more general and summary terms, the logic of capitalist accumulation has had a clear impact on infrastructure operations over time; the logic of requisite variety has now a clear albeit contingent impact on infrastructure operations in the Anthropocene. The difference between the two is due in large part to shifting infrastructural interconnectivities: then, now and ahead.
NB. The above has been spliced and sutured together from a number of previous publications and blogs. The original research for the above was undertaken and co-authored with my colleague Paul R. Schulman. As such, I am responsible for any misleading simplifications or hydraulic interpretations that have crept into the preceding.

2 thoughts on “How analyses of risk and resilience lead to the real-time mismanagement in the operations of critical infrastructures”